
Introducing the 4.1 version of Graphlytic - graph visualization software, designed to help you gain insights into complex networks and data structures. With powerful features and an intuitive user interface, Graphlytic is the perfect tool for anyone working with graphs and networks, from data scientists to business analysts.
This release is packed with new features and improvements. We can't cover everything in this blog post, so please take a look at the release notes if you want to know more about all of them: Release Notes. The most important changes can be summarized in these topics:
Graphlytic's fulltext search architecture was completely rethought and reimplemented. We have introduced the concept of a Search Connector and implemented a few of them to cover all supported databases. Every project can use different Search Connector to provide fulltext search capabilities for users of that project and every Search Connector implements searching for nodes and also relationships. Detailed information on different configuration options is in our documentation.
Currently, supported Search Connectors are:
There are quite a lot of things that can be configured in Graphlytic on the platform level. More info about all of them can be found on the Application Settings page in our documentation. In this release, we have added a new UI for existing configuration options to make usage much easier. Let's have a look at some of them.
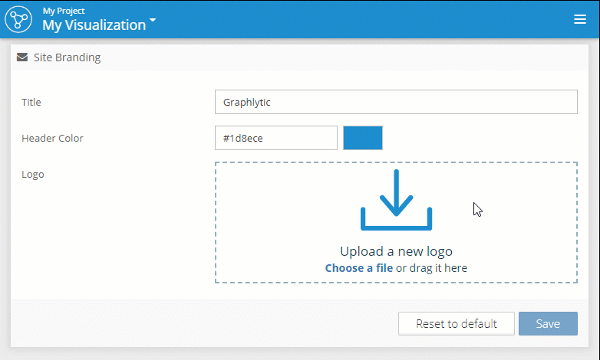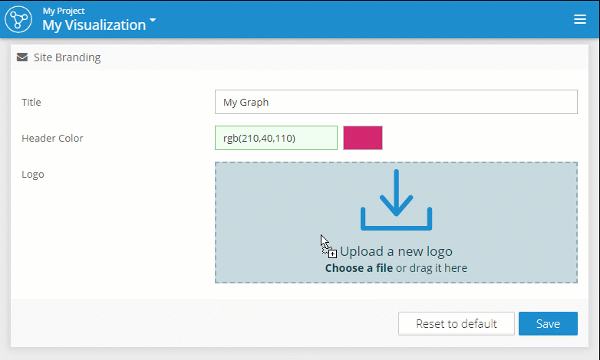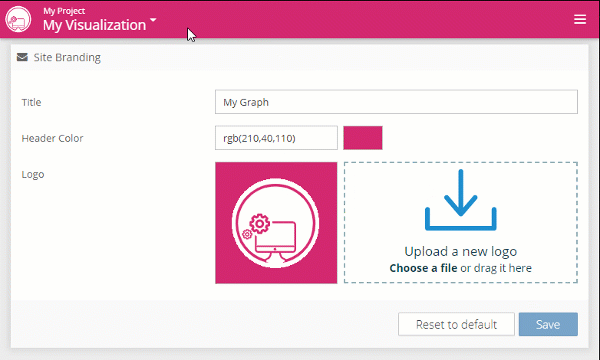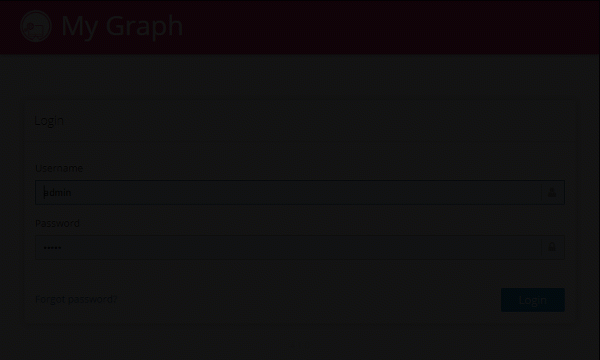
With the new branding options, it's easy to customize the logo in the top left corner, the color of the header, and even the name of the application shown on the login page. This way you can configure Graphlytic to better fit your organization design-wise.
Uploading and managing custom icons for your graph visualizations has become much easier with the new icon management panel. Simply upload whole zip files with icons, or upload single icons, create icon groups, and then link the icon groups to projects.
![]()
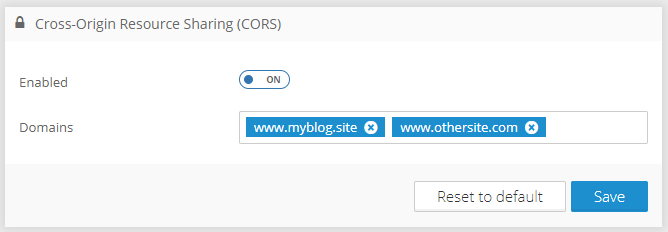
A few releases back we added the option to include Graphlytic in other applications using iFrame. In this release, we are adding the option to turn on/off the iFrame embedding and also to control domains where Graphlytic can be embedded.
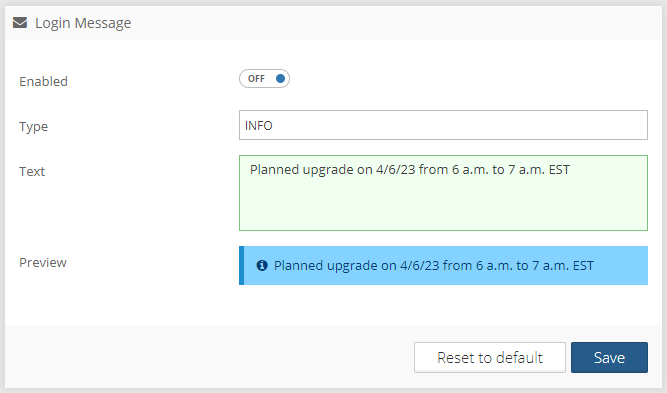
For situations like a scheduled outage due to an upgrade, or planned change of domain of your Graphlytic installation we have added the option to create a simple message on the login page for every user to see before logging into the application. Simply choose the type of message (Info, Warning, Danger, Success) which is represented by a different color, type the message, and turn it on. A preview of the message is also available.
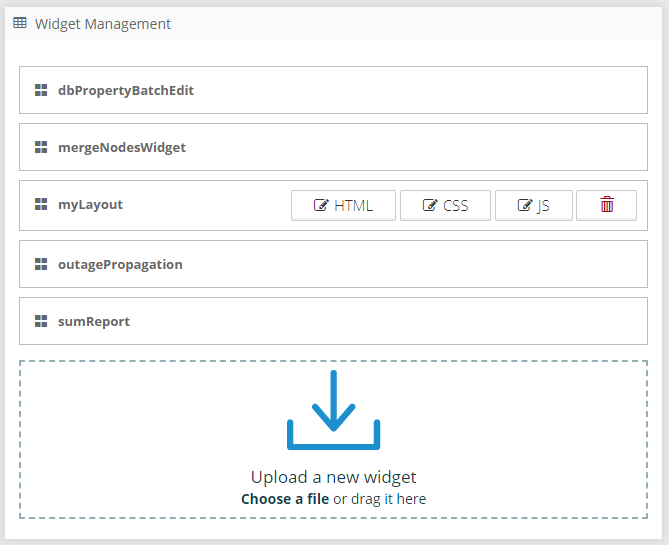
Widgets are a powerful way how to extend the functionality of the visualization for specific use cases. Every widget is a package consisting of one HTML, one JavaScript, and one CSS file.
We are implementing custom widgets for our clients routinely and starting with this release we are moving closer to opening the widgets API for everyone. There is still a lot of work on our side to create a stable API with good documentation but it's much easier to manage widgets, upload, delete, and configure them for different projects.
Included is also a new code editor with syntax highlighting and code completion. There are also a couple of internal widgets bundled with the application, and new widgets can be uploaded easily and configured on the spot.
In visualization, we have been focused mainly on hardening and optimizing features for all supported graph databases. There are, however, also a couple of new features and significant improvements that I would like to mention here.
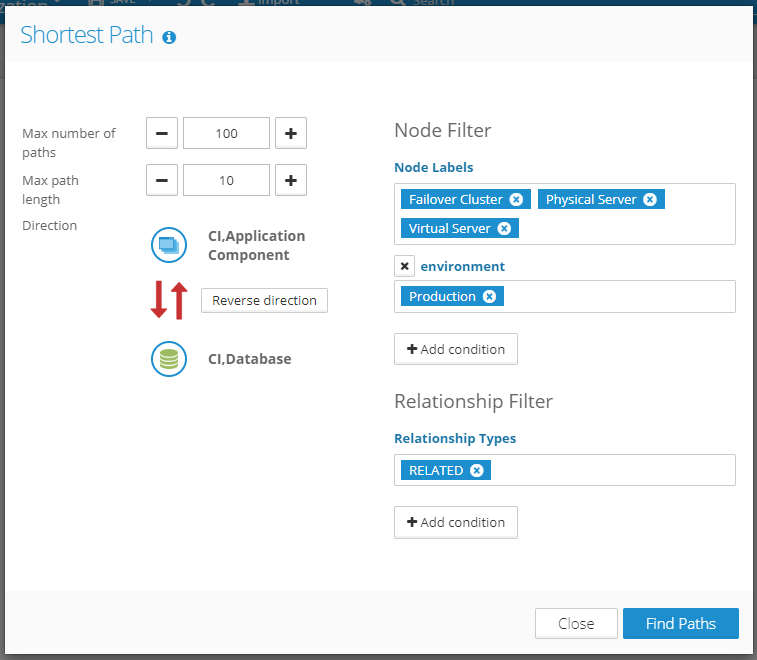
Condition for shortest path algorithm can be used to prefilter paths that will be searched and returned from the graph database. This can greatly improve performance on highly connected graphs and reduce the number of returned results. Besides the basic configuration options like max number of returned paths and max length of paths, there is also the option to search for paths only in a specific direction and add detailed conditions that the elements on the path have to meet.
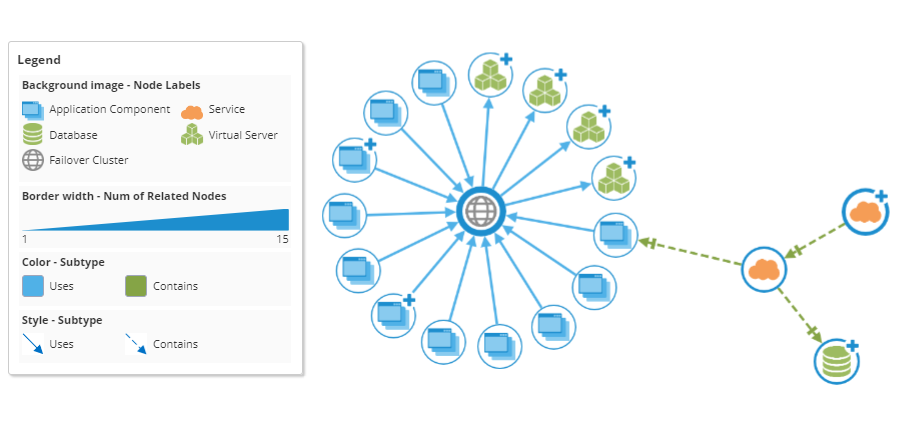
Legend in visualization was in our backlog for a very long time. Finally, in this release, we are releasing the legend with quite a few configuration options (size, position, etc. For a full list of options please read our documentation).
Legend for every style mapping can be turned on directly in the visualization in the Style section of the settings tab. Legend is also exported in the image export of the visualization (if turned on).
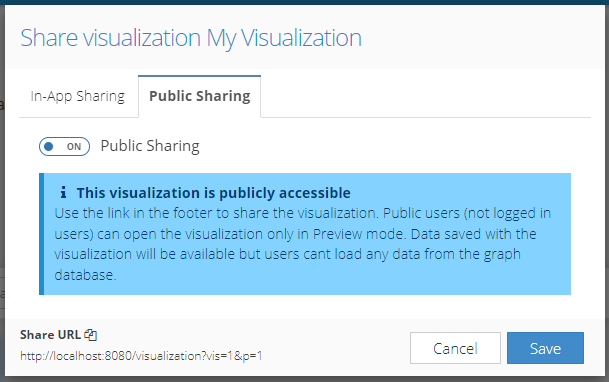
For the first time saved visualizations can be shared with the public. All you need to do is mark any saved visualization as public and then share a URL link that will open the visualization without the need to log into the application. Visualization opened by an unauthenticated user is opened in "preview" mode where no graph database calls can be made. Only data saved with the visualization are shown (snapshot of the saved state).
Simply open the sharing window of any saved visualization, turn on the public sharing option, copy the URL in the footer by clicking on it and save the changes.
Every publicly shared visualization is marked with an orange label "PUBLIC" to quickly identify them on the projects page.

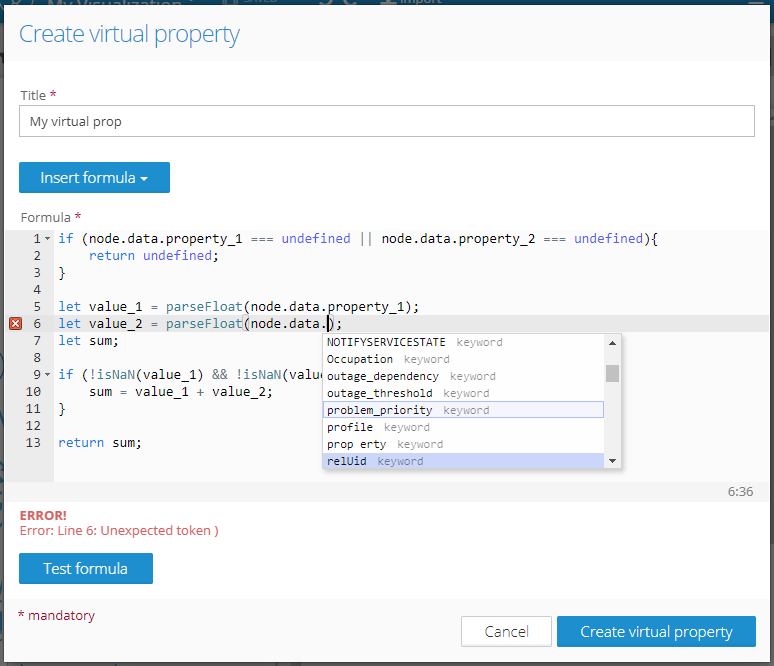
Virtual properties are like Excel formulas but for graphs... and using JavaScript. It's a really cool way how to bring more life to your graphs, add values calculated based on data stored in the graph, create flags, concatenated titles, conditional values, and much more. In this release, we have added a graph traversing API, and a new editor with code completion for virtual properties.
This is how the new virtual property editor with syntax highlighting, code completion, line grouping, search, and syntax checker looks like:
The new Graph traversing API for virtual properties allows traversing the graph (elements loaded in the visualization) in the virtual property's code using methods like:
This way it's possible to write a formula for the calculation of a property based on data from elements several hops away from the evaluated node. E.g. calculate the wealth of a Person node based on the relative percentage ownership of linked Company nodes by accessing all Person nodes linked to these Company nodes. For more info on virtual properties please read the documentation.
Demtec, s.r.o.
Karpatské námestie 10A
831 06 Bratislava
Slovakia
ID: 47807890
VAT ID: SK2024104434
EMAIL: info@graphlytic.com
TEL: +421 944 289 809





