The Hybrid Data Model is Graphlytic's solution for knowledge graphs with near real-time analysis of transactions with time-slicing (the Timeline feature). Its advantages are easy scaling, time slicing without the need for precalculating data, and instant changes in the graph without the need for extensive recalculations every time a new transaction is added.
This approach can be used in many different use cases, e.g.:
- financial transactions (money flow)
- process mining (document transactions)
- communication (phone logs, email logs)
- system activity (trace logs, server logs, API logs)
The Hybrid Data Model is an approach using the combination of two data sources in the visualization:
- Graph Database - providing the graph structure and time-insensitive data, or all-time aggregates
- Document Database (like SOLR, Elastic, or any other document-based search engine) - storing detailed transactions and providing time-sensitive aggregations for graph relationships
After configuration of the Hybrid Data Model, Graphlytic's visualization is able to seamlessly combine these two data sources to provide a unified view where the graph is enriched with aggregated time-sliced data from the document DB.
As an example imagine the visualization of phone logs, where nodes are persons and relationships are individual calls from the log. This approach is very straightforward but usable only for a smaller number of calls. With potentially thousands of calls between some persons, this model can quickly run into performance issues on the graph database level or in the visualization. One solution is to have only one relationship between any two persons that have communicated at least once and calculate aggregated values like the number of calls, the average length of a call, etc. But then adding new calls and doing time-slicing becomes a computationally intensive task requiring more resources. Graphlytic's Hybrid Data Model is a balance between a lean graph model and the possibility to do fast time-slicing, accessing the detailed data anytime, and have near-real-time results.
Oops, Diagram Unavailable
This diagram can't be displayed. It may have been moved or deleted, or the page's access settings may be preventing it from loading. Pages with restricted access must also include Gliffy Diagrams in their allowed list.
Configuration
To configure the hybrid data model, turn on the switch a configure the model by clicking on the "Configure" button, which displays the modal window for "Hybrid Data Model Configuration".
There are two major ways how to enable the Hybrid Data Model:
- using SOLR as the document DB together with Graphlytic's integrated SOLR client
- using another document DB with a custom implementation of the necessary API
Integrated SOLR client
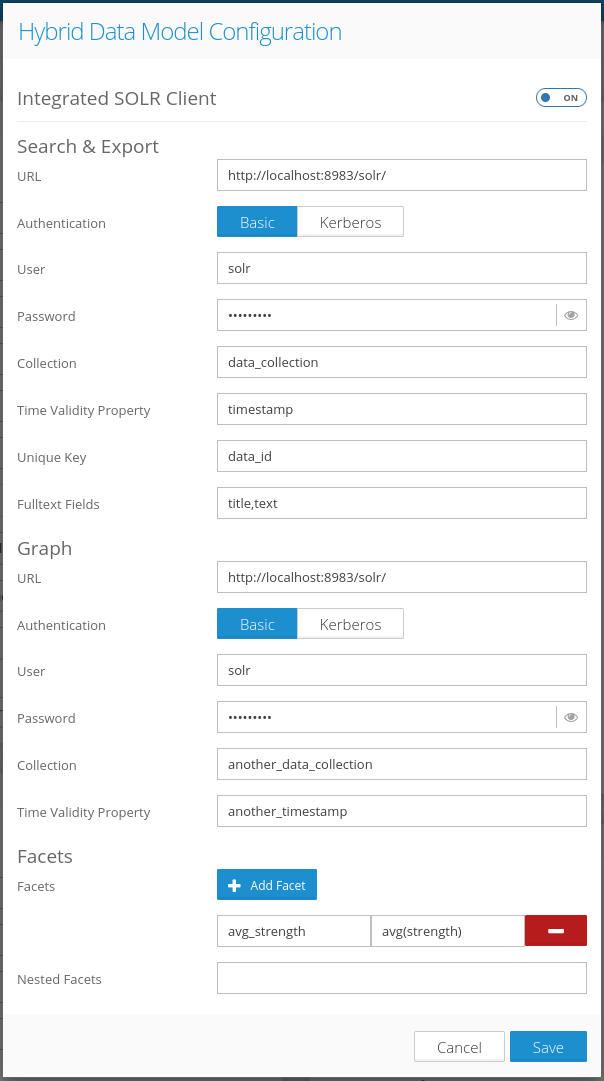
The SOLR client for the Hybrid Data Model works with one or two SOLR collections, providing more flexibility in scaling the solution. These collections have a different purpose in the model:
- Search & Export - this collection should store the detailed data of the transactions (documents) and providing fulltext search and filtering, returning the documents as a result.
- Graph - this collection should store only data necessary to compute the aggregated values for relationship enrichment in the graph.
In case you don't need to store a lot of textual data in the documents it's possible to use the same SOLR collection in both parts of the configuration.
When the integrated SOLR client is enabled, the modal window displays these configuration options:
Custom implementation of the Hybrid Model API
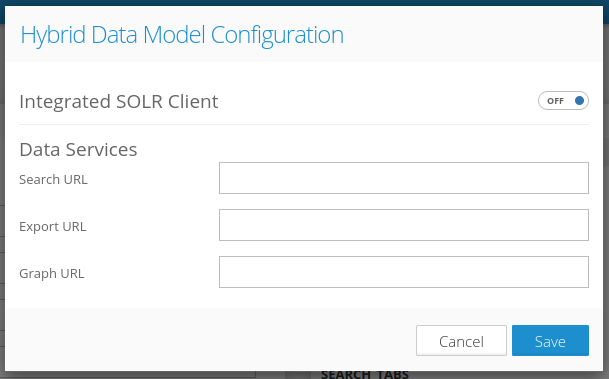
When other than SOLR document DB is used, a custom implementation of a few API endpoints is needed:
- Search URL - endpoint providing fulltext search and filtering in the documents.
- Export URL - endpoint returning a file with exported documents based on the requested filter condition.
- Graph URL - endpoint returning aggregated time-sliced values for individual graph relationships based on requested relationship ID and time interval.