Required Permission: Jobs management (Read more about permissions in User Groups)
Groovy scripts can be used in ETL scripts, so writing scripts to delete files on the local disk (and other potentially dangerous tasks) is possible. Please be careful when writing scripts and granting the Jobs management permission to users.
Table of contents
Graphlytic has an embedded instance of the Scriptella framework, which is the foundation of the ETL engine used for managing automation jobs. These jobs usually import data into a graph database, run queries, and send emails with data results (notifications in case a forbidden pattern is found in the graph, weekly reports, etc.).
1. ETL engine
The ETL engine contains several database drivers: PostgreSQL, MySQL, MSSQL, Oracle, DB2, Derby, H2, HSQLDB, Sybase, and XSL. Not all JDBC drivers are included in Graphlytic, but they can be included as external jar files. Contact us if you need to plug in a jar file; we will help you.
ETL engine contains other drivers: CSV, Neo4j, Mail, Groovy, Log, Text, XPath and more. ETL engine is configured in XML.
Using a combination of drivers, you can create many scenarios. Here is a small overview of configurable scenarios. Some examples are in the Administration manual (see ETL job examples).
The Scriptella engine with several custom drivers is used as the ETL module in Graphlytic. Please see the reference documentation of Scriptella for details : http://scriptella.org/reference/
The ETL engine contains several drivers for database connection and data manipulation (JDBC): Postgresql, MySQL, MSSQL, Oracle, DB2, Derby, H2, HSQLDB, Sybase, and XSL. However, not all JDBC drivers are included in Graphlytic and can be included in a custom build of Graphlytic. Please get in touch with us for more information.
The ETL engine also contains other drivers, such as CSV, Neo4j, Mail, Groovy, Log, Text, XPath, and more. By combining these drivers, many automation scenarios for data processing, pattern searching, logging, and notifications can be created.
ETL jobs are XML files that can be executed on demand, planned to execute at a defined time, or periodically executed (with CRON-like triggers).
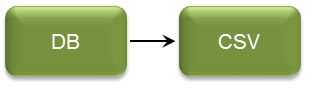
Example 1: Load data from the SQL database by using an SQL query and insert every record of the result into a CSV file.
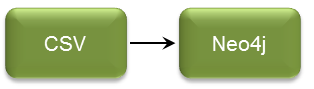
Example 2: Load data from CSV into Neo4j using Cypher (LOAD CSV command).

Example 3: Load data from SQL database using a SQL query, transform every record of the result by Groovy (for example, remove special characters), then insert every transformed record into a CSV file. Then, load data from the CSV file into Neo4j using Cypher (LOAD CSV command).

Example 4: Load data from Neo4j using a Cypher query, transform every record of the result using Groovy, and append every record to the result string. Then, send the string as HTML mail to several recipients.
See the ETL job examples page for more information.
2. Manage Jobs
The Jobs page can be accessed using the Main menu (top right). The user has to have appropriate permissions to access this page.
The page shows a list of all jobs and allows the user to manage them, e.g. creating new jobs, editing existing ones and running them.
When any of the jobs are running, the Auto-refresh option is available to automatically see any changes in the state of the job (refreshed every 30 seconds). Similarly, an auto-refresh option is available in the job history, and the refresh interval can be adjusted here.
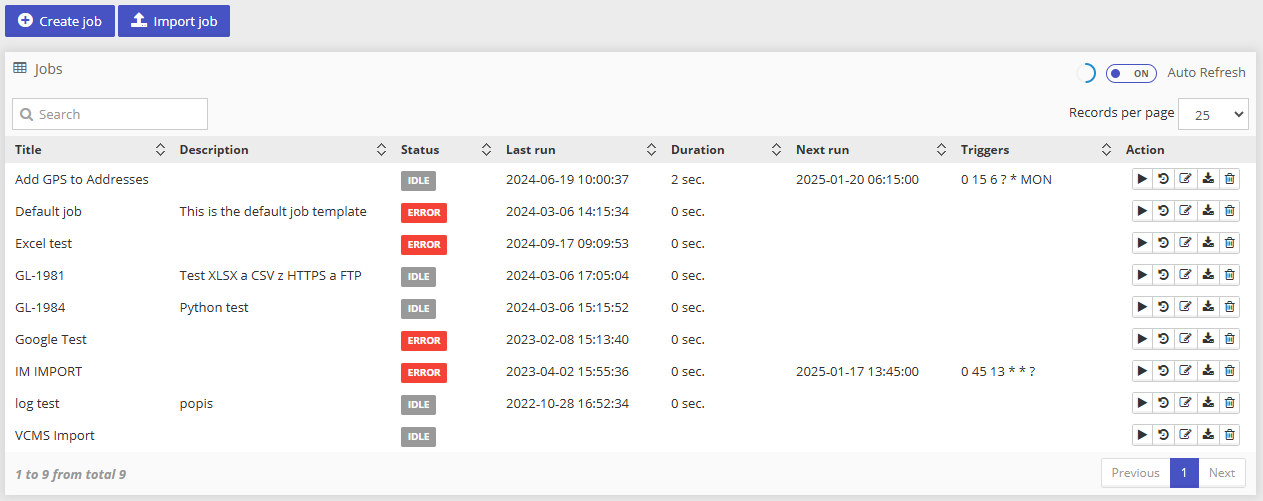
Job actions (icons on the right side of every job):
Run - job is started immediately.
History - view the history of executions, e.g. when the job started and finished. If there was an error during execution, the error message can be found here.
Update - you can change job details.
Export - export the job into a file.
Delete - confirmation dialog is shown. The job is deleted after confirmation.
2.1. Create a new job
A new job can be created on the Jobs page using the “Create job” button.
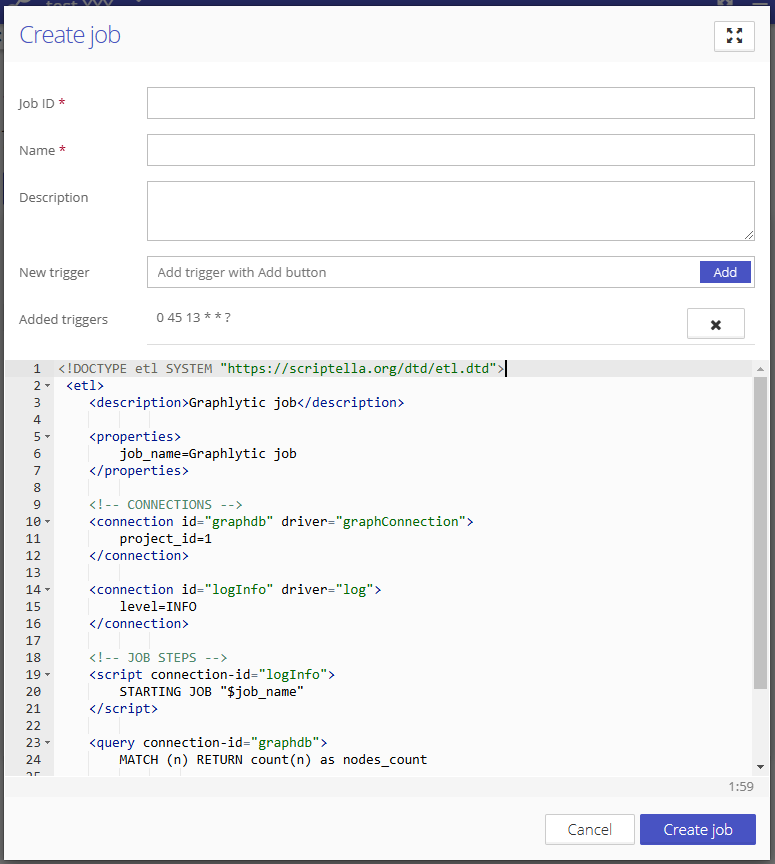
Fill out the form:
Job ID - A unique string used to identify the job in the API. It cannot be changed after the job is created.
Name - A user-friendly job name. It can be changed anytime.
Triggers - To run the job periodically, enter a trigger into the "New trigger" field and click on the "Add" button. To remove the trigger, select the "X" icon. See the chapter “Trigger” for more information and examples.
Script - Actual XML script representing the steps of a job.
2.2. Import job from a file
Jobs exported into a file (see the job actions listed above) can be imported using the “Import job” button.
Existing jobs are checked to see if the Job ID of the imported job has already been used. If yes, an error is shown, and the job is not imported.
2.3. Triggers
The ETL engine uses cron-like expressions as triggers. A cron expression is a string of 6 or 7 fields separated by spaces. Fields can contain any of the allowed values and combinations of the allowed special characters for that field. The fields are as follows:
Field Name | Mandatory | Allowed Values | Allowed Special Characters |
|---|---|---|---|
Seconds | YES | 0-59 | , - * / |
Minutes | YES | 0-59 | , - * / |
Hours | YES | 0-23 | , - * / |
Day of month | YES | 1-31 | , - * ? / L W |
Month | YES | 1-12 or JAN-DEC | , - * / |
Day of week | YES | 1-7 or SUN-SAT | , - * ? / L # |
Year | NO | empty, 1970-2099 | , - * / |
Examples of cron expressions:
Every Monday at 6:15 am: 0 15 6 ? * MON
Every day at 13:45: 0 45 13 * * ?
Every 15 minutes: 0 0/15 * * * ?
Every 30 seconds: 0/30 * * * * ?
More examples can be found in the Quartz's library tutorial here: http://www.quartz-scheduler.org/documentation/quartz-2.3.0/tutorials/crontrigger.html